爬虫实战
实战1:爬取某视频首页视频
爬取内容:

爬取结果:
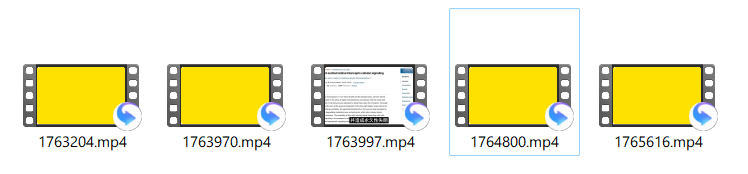
实现过程及思路:
从网页主页url中打开控制台,获取主页的html源码,利用
xpath解析得到这一块的子页面href。打开子页面的源代码,发现视频并不在其中,则通过network中的Fetch/XHR查找视频来源。
从中得到Request URL,进行requests.get发现获取失败,并得到以下内容。

分析得到结果,是防盗链反爬导致的,回头找network内headers属性,将User-Agent,Cookie加入headers字典,再次使用requests.get发现仍然如此 ,最后发现是Referer防盗链造成的,Referer的值为子页面的href,将其组成键值对加入headers字典,再次进行requests.get,得到srcUrl。
对srcUrl进入发现还有最后一层反爬,通过比对正确的视频url和srcUrl发现:srcUrl是通过真正的url与systemTime组合修改的,找到其修改规律,用replace方法将systemTime改为f'cont-{video_id}',得到最后正确的视频链接。
通过最后的write(requests.get(true_url).content)得到所需视频。
实现代码:
"""
7.13 Kevin
防盗链处理 某视频 视频爬虫 爬取首页第一个大div里面所有视频
"""
import requests
from lxml import html
etree = html.etree
url = 'https://www.pearvideo.com/'
res = requests.get(url)
tree = etree.HTML(res.text)
href_list = tree.xpath('//*[@id="vervideoTlist"]/div//@href')
print(href_list)
for href in href_list:
url = 'https://www.pearvideo.com/'+ href
video_id = url.split('_')[1]
params = {
'contId': video_id
}
videoStatus = requests.get('https://www.pearvideo.com/videoStatus.jsp', params)
new_url = videoStatus.url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'Cookie': '__secdyid=e9d7070e31f729879bd4edec9f3db4567721f9f23769837d021657708580; acw_tc=2f624a1916577085808321223e1c9d5da783477514d7ff177f8220c470bbf8; JSESSIONID=2EF2FE6E5DE5C57BD7DAA3C0C372BE69; PEAR_UUID=dd85645b-e891-4615-a677-a8d2db1df2a2; _uab_collina=165770858183026495245603; Hm_lvt_9707bc8d5f6bba210e7218b8496f076a=1657708583; p_h5_u=B2141296-37D6-4117-87E8-E50BC33AFE84; Hm_lpvt_9707bc8d5f6bba210e7218b8496f076a=1657708644; SERVERID=ed8d5ad7d9b044d0dd5993c7c771ef48|1657708664|1657708580',
'Referer': url
}
resp = requests.get(new_url, headers=headers)
resp_json = resp.json()
fake_url = resp_json['videoInfo']['videos']['srcUrl']
# 这里用切片方法组合得到真实的url再组合,没用对脑子,非常复杂
# srcUrl = https://video.pearvideo.com/mp4/third/20220712/1657710591280-11905134-122533-hd.mp4
# part_list1 = fake_url.split('/')[-1].split('-')[1:]
# part_list2 = fake_url.split('-')[0].split('/')[0:-1]
# part_left = ''
# part_right = ''
# for item in part_list1:
# part_right += item+'-'
# for it in part_list2:
# part_left += it+'/'
# true_url = part_left + 'cont-'+video_id + '-' + part_right.strip('-')
# 以下使用replace方法
systemTime = resp_json['systemTime']
true_url = fake_url.replace(systemTime, f"cont-{video_id}")
#print(true_url)
video_name = f'{video_id}.mp4'
with open('video/'+video_name, 'wb') as fw:
resp2 = requests.get(true_url)
fw.write(resp2.content)"""
7.13 Kevin
防盗链处理 某视频 视频爬虫 爬取首页第一个大div里面所有视频
"""
import requests
from lxml import html
etree = html.etree
url = 'https://www.pearvideo.com/'
res = requests.get(url)
tree = etree.HTML(res.text)
href_list = tree.xpath('//*[@id="vervideoTlist"]/div//@href')
print(href_list)
for href in href_list:
url = 'https://www.pearvideo.com/'+ href
video_id = url.split('_')[1]
params = {
'contId': video_id
}
videoStatus = requests.get('https://www.pearvideo.com/videoStatus.jsp', params)
new_url = videoStatus.url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'Cookie': '__secdyid=e9d7070e31f729879bd4edec9f3db4567721f9f23769837d021657708580; acw_tc=2f624a1916577085808321223e1c9d5da783477514d7ff177f8220c470bbf8; JSESSIONID=2EF2FE6E5DE5C57BD7DAA3C0C372BE69; PEAR_UUID=dd85645b-e891-4615-a677-a8d2db1df2a2; _uab_collina=165770858183026495245603; Hm_lvt_9707bc8d5f6bba210e7218b8496f076a=1657708583; p_h5_u=B2141296-37D6-4117-87E8-E50BC33AFE84; Hm_lpvt_9707bc8d5f6bba210e7218b8496f076a=1657708644; SERVERID=ed8d5ad7d9b044d0dd5993c7c771ef48|1657708664|1657708580',
'Referer': url
}
resp = requests.get(new_url, headers=headers)
resp_json = resp.json()
fake_url = resp_json['videoInfo']['videos']['srcUrl']
# 这里用切片方法组合得到真实的url再组合,没用对脑子,非常复杂
# srcUrl = https://video.pearvideo.com/mp4/third/20220712/1657710591280-11905134-122533-hd.mp4
# part_list1 = fake_url.split('/')[-1].split('-')[1:]
# part_list2 = fake_url.split('-')[0].split('/')[0:-1]
# part_left = ''
# part_right = ''
# for item in part_list1:
# part_right += item+'-'
# for it in part_list2:
# part_left += it+'/'
# true_url = part_left + 'cont-'+video_id + '-' + part_right.strip('-')
# 以下使用replace方法
systemTime = resp_json['systemTime']
true_url = fake_url.replace(systemTime, f"cont-{video_id}")
#print(true_url)
video_name = f'{video_id}.mp4'
with open('video/'+video_name, 'wb') as fw:
resp2 = requests.get(true_url)
fw.write(resp2.content)实战2:爬取某音乐评论
爬取内容:
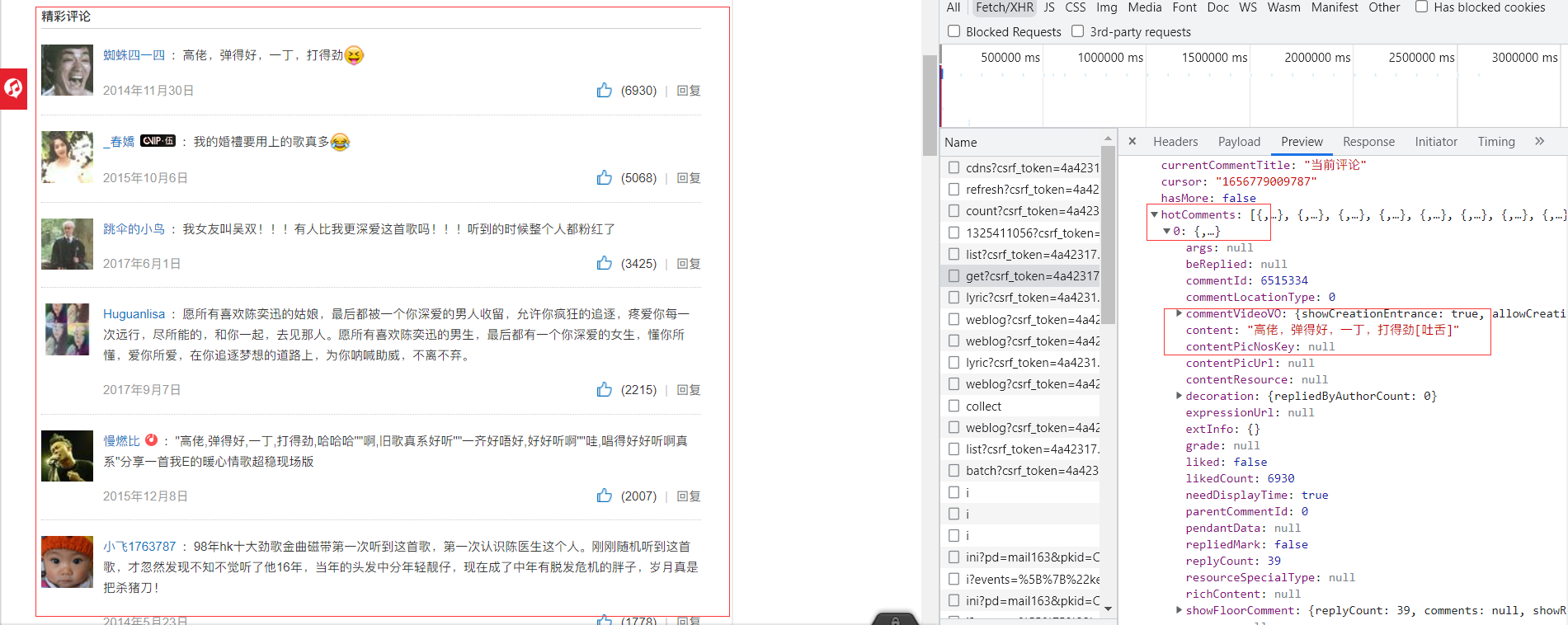
爬取结果:
实现过程及思路:
查看网页源代码,发现评论并没有在源代码内,转而找NetWork下对应评论的请求,查看headers。
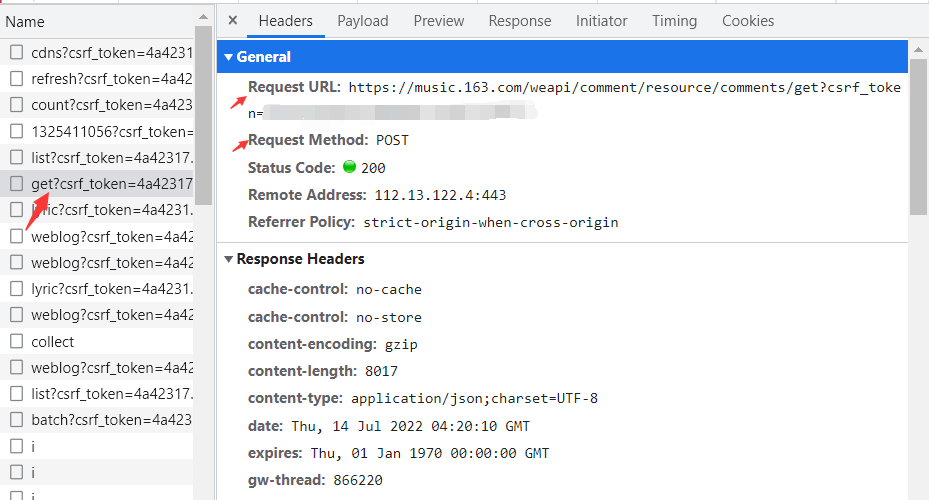

发现From Data内数据被加密。
解决思路:
- 找到未加密的参数
- 参考原来的加密逻辑加密自己的参数
- 请求到网址,得到加密信息
步骤:
寻找加密过程:
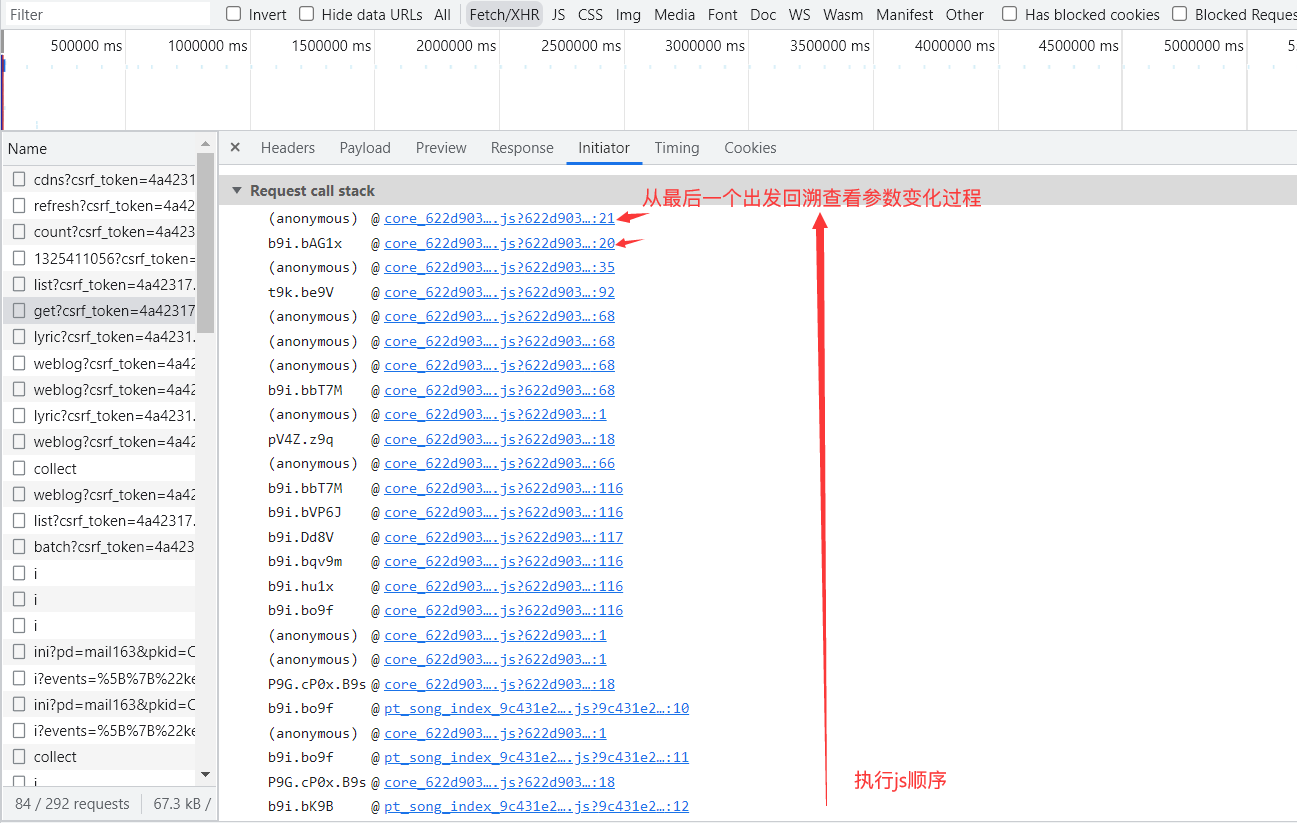
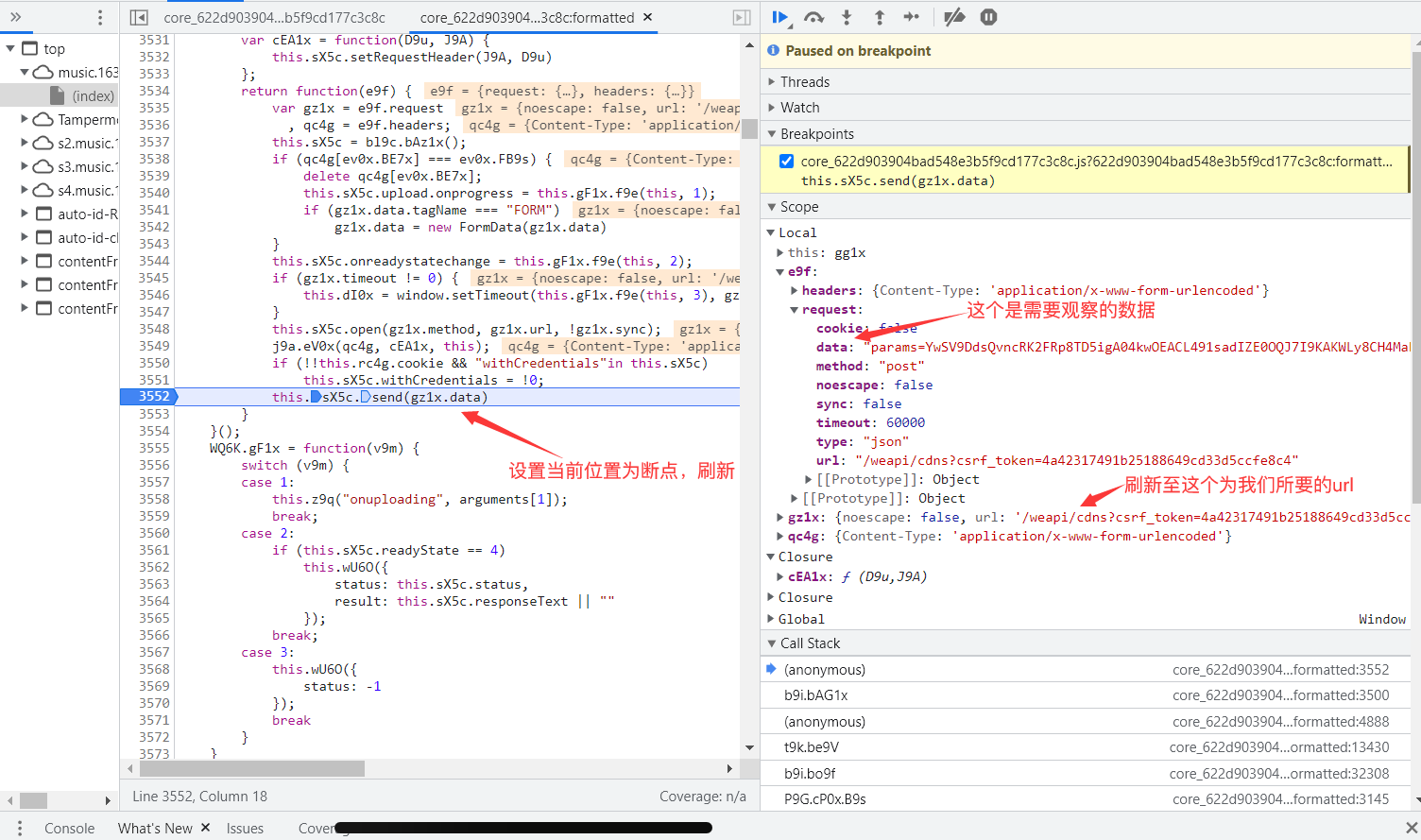
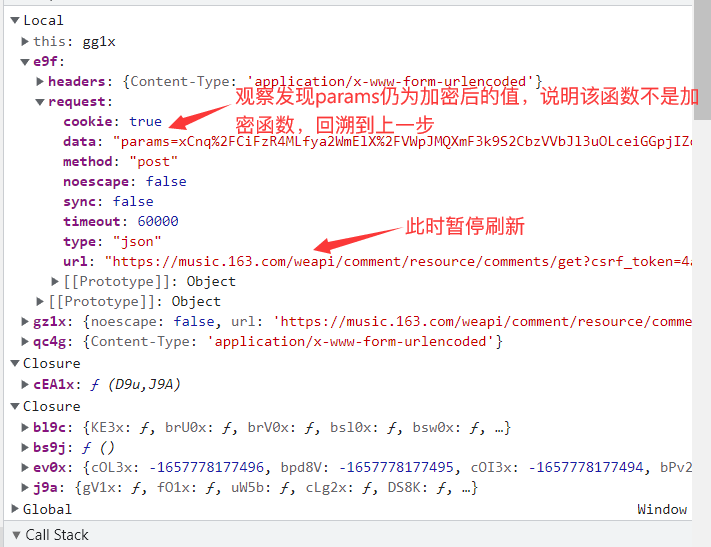
进入Call Stack查看上一步的,直至找到数据未加密的时候:
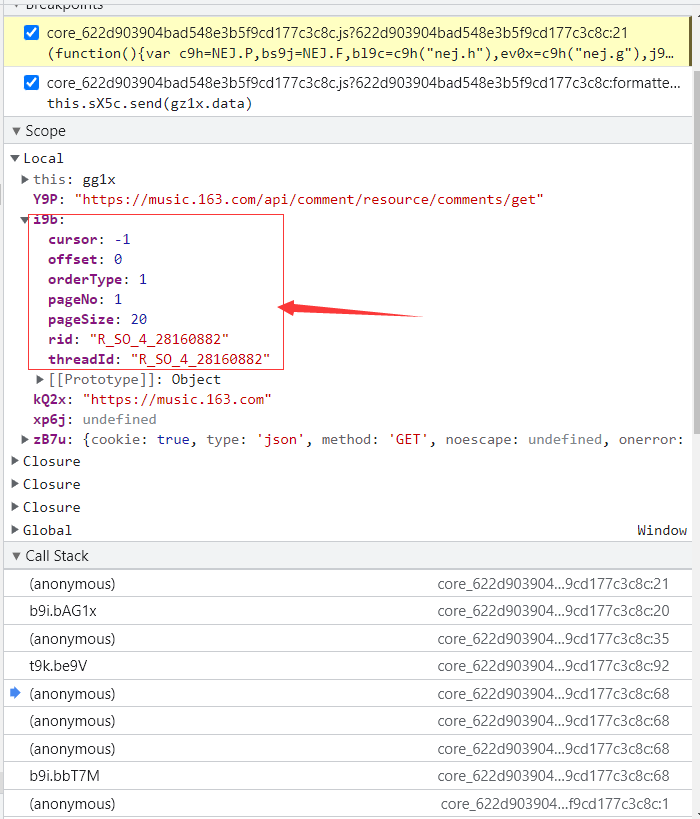
观察后可得到加密函数如下:
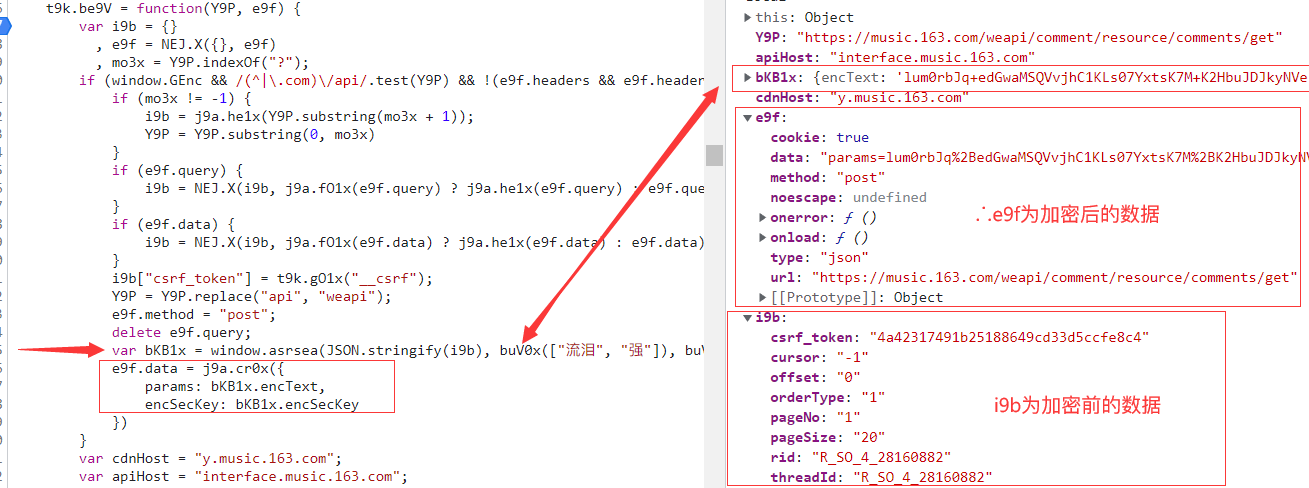
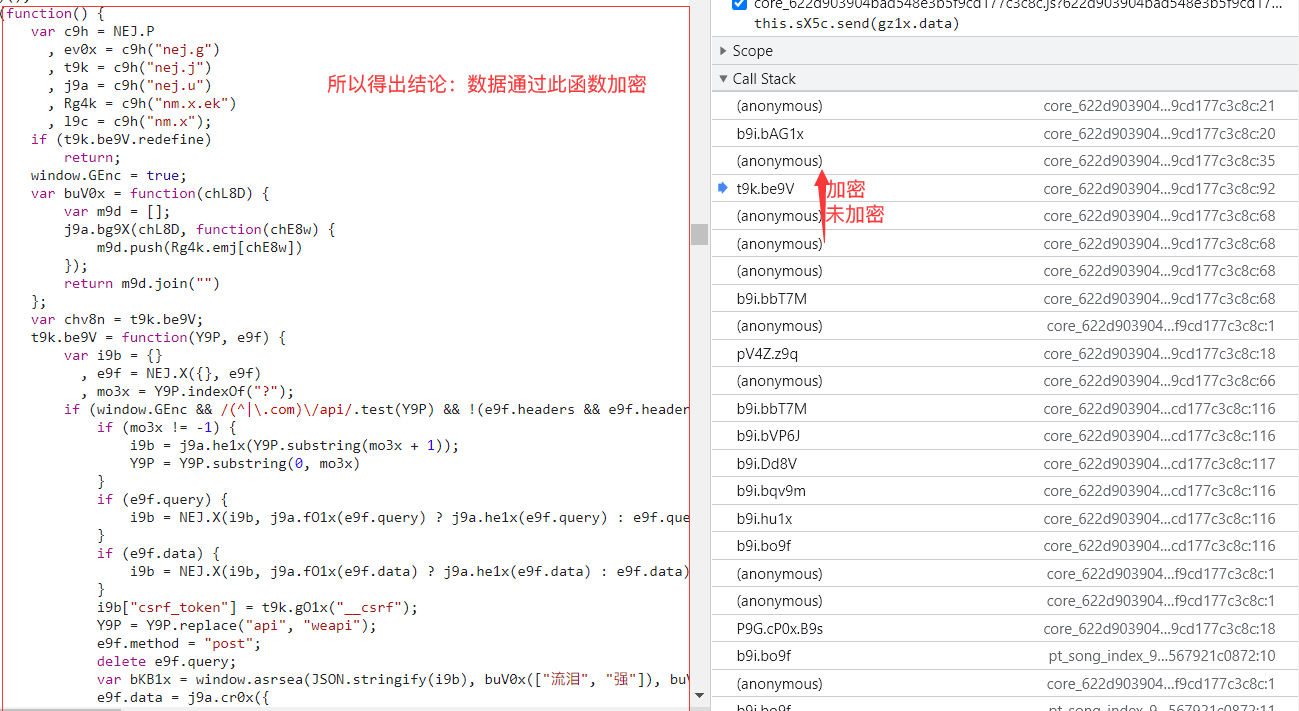
∴加密的过程为 windows.asrsea(加密前数据,xxx,xxx)
进一步找asrsea函数组的定义:
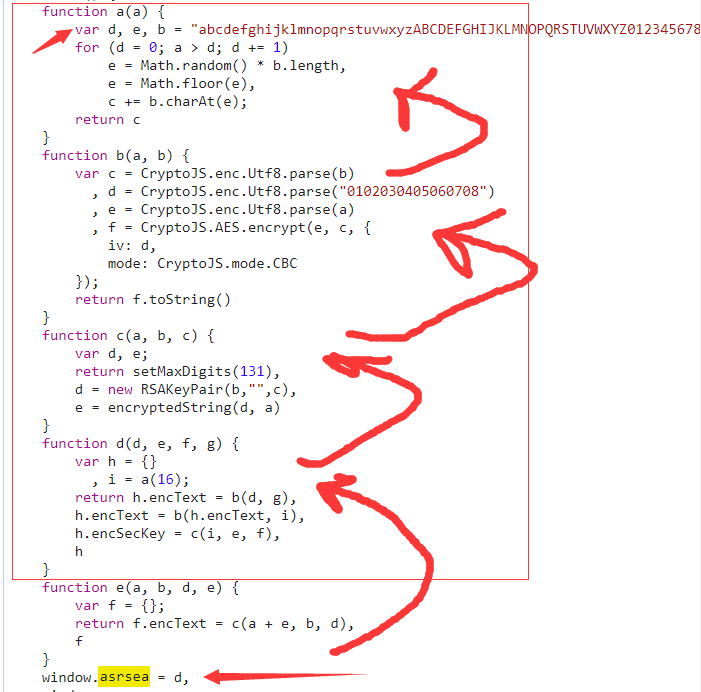
所以具体实参对应:d=data参数, e=buV0x(["流泪", "强"]), f=buV0x(Rg4k.md), g=buV0x(["爱心", "女孩", "惊恐", "大笑"])【参数efg可以从Console运行得出以下结果】
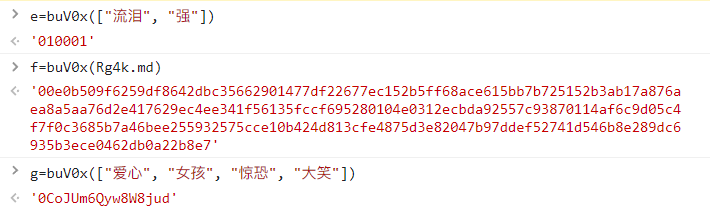
分析函数运行过程:在代码里有
实现代码:
"""
7.14 Kevin
网易云音乐 热评 爬虫
"""
import requests
from Crypto.Cipher import AES
from base64 import b64encode
import json
d = '010001'
f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
g = '0CoJUm6Qyw8W8jud'
i = "kyM74e2babr6Ktf3"
data = {
"rid": "R_SO_4_28160882",
"threadId": "R_SO_4_28160882",
"pageNo": "1",
"pageSize": "20",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"csrf_token": "4a42317491b25188649cd33d5ccfe8c4"
} # data为解密前的数据
def get_encSecKey():
return "5015aaf2b9d0c1487908bf12cd0afdac506c4e7527cb6805ead6f4f6fa363aed69d876a0a9ecf18caaadc09ff9a61dcbf868657e15bbd0a24a44c41b499e19d5e9eede71d3f99232f965515aef8fc282f15b7ee7816fd9b5ac2d3784f385f03213ea8882edafe47bf88b3cd0f120f441f9246348fb2d75b6799f8548b021b04b"
def get_params(data): # 默认所得为字符串
first = enc_params(data, g)
second = enc_params(first, i)
return second
def to_16(data):
pad = 16 - len(data) % 16
data += chr(pad)*pad
return data
def enc_params(data, key):
iv = '0102030405060708'
data = to_16(data)
aes = AES.new(key=key.encode("utf-8"), IV=iv.encode('utf-8'), mode=AES.MODE_CBC) # 创建加密器
bs = aes.encrypt(data.encode('utf-8')) # 加密,加密的内容长度必须是16的倍数,
return str(b64encode(bs), "utf-8")
url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token=4a42317491b25188649cd33d5ccfe8c4'
# 处理加密过程
"""
function a(a) { # 返回随机16位字符串
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1) # 循环16次
e = Math.random() * b.length, # 随机数
e = Math.floor(e), # 取整
c += b.charAt(e); # 取字符串
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b) # b是秘钥
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a) # e是数据
, f = CryptoJS.AES.encrypt(e, c, { # c是加密的秘钥
iv: d, # 偏移量
mode: CryptoJS.mode.CBC # 加密模式
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16); # i是16位随机字符串
return h.encText = b(d, g), # g是秘钥
h.encText = b(h.encText, i), # 返回params,i是秘钥
h.encSecKey = c(i, e, f), #得到encSecKey 8===D 此时i已经是一个定制,所以可def一个函数get_encSecKey
h
}
具体调用: var bKB1x = window.asrsea( d=JSON.stringify(i9b), e=buV0x(["流泪", "强"]), f=buV0x(Rg4k.md), g=buV0x(["爱心", "女孩", "惊恐", "大笑"]));
d:数据,e
"""
resp = requests.post(url, data={
"params": get_params(json.dumps(data)),
"encSecKey": get_encSecKey()
})
print(resp.json())"""
7.14 Kevin
网易云音乐 热评 爬虫
"""
import requests
from Crypto.Cipher import AES
from base64 import b64encode
import json
d = '010001'
f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
g = '0CoJUm6Qyw8W8jud'
i = "kyM74e2babr6Ktf3"
data = {
"rid": "R_SO_4_28160882",
"threadId": "R_SO_4_28160882",
"pageNo": "1",
"pageSize": "20",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"csrf_token": "4a42317491b25188649cd33d5ccfe8c4"
} # data为解密前的数据
def get_encSecKey():
return "5015aaf2b9d0c1487908bf12cd0afdac506c4e7527cb6805ead6f4f6fa363aed69d876a0a9ecf18caaadc09ff9a61dcbf868657e15bbd0a24a44c41b499e19d5e9eede71d3f99232f965515aef8fc282f15b7ee7816fd9b5ac2d3784f385f03213ea8882edafe47bf88b3cd0f120f441f9246348fb2d75b6799f8548b021b04b"
def get_params(data): # 默认所得为字符串
first = enc_params(data, g)
second = enc_params(first, i)
return second
def to_16(data):
pad = 16 - len(data) % 16
data += chr(pad)*pad
return data
def enc_params(data, key):
iv = '0102030405060708'
data = to_16(data)
aes = AES.new(key=key.encode("utf-8"), IV=iv.encode('utf-8'), mode=AES.MODE_CBC) # 创建加密器
bs = aes.encrypt(data.encode('utf-8')) # 加密,加密的内容长度必须是16的倍数,
return str(b64encode(bs), "utf-8")
url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token=4a42317491b25188649cd33d5ccfe8c4'
# 处理加密过程
"""
function a(a) { # 返回随机16位字符串
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1) # 循环16次
e = Math.random() * b.length, # 随机数
e = Math.floor(e), # 取整
c += b.charAt(e); # 取字符串
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b) # b是秘钥
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a) # e是数据
, f = CryptoJS.AES.encrypt(e, c, { # c是加密的秘钥
iv: d, # 偏移量
mode: CryptoJS.mode.CBC # 加密模式
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16); # i是16位随机字符串
return h.encText = b(d, g), # g是秘钥
h.encText = b(h.encText, i), # 返回params,i是秘钥
h.encSecKey = c(i, e, f), #得到encSecKey 8===D 此时i已经是一个定制,所以可def一个函数get_encSecKey
h
}
具体调用: var bKB1x = window.asrsea( d=JSON.stringify(i9b), e=buV0x(["流泪", "强"]), f=buV0x(Rg4k.md), g=buV0x(["爱心", "女孩", "惊恐", "大笑"]));
d:数据,e
"""
resp = requests.post(url, data={
"params": get_params(json.dumps(data)),
"encSecKey": get_encSecKey()
})
print(resp.json())