re模块
import re
findall:
匹配字符串中所有符合正则的内容,返回迭代器。
python
lst = re.findall(r"\d+", "我的电话号码一个是:12345,另一个是:13579")
print(lst)
# ['12345','13579']lst = re.findall(r"\d+", "我的电话号码一个是:12345,另一个是:13579")
print(lst)
# ['12345','13579']finditer:
匹配字符串中所有的内容,返回迭代器,获取内容需要group()。
python
it = re.finditer(r"\d+", "我的电话号码一个是:12345,另一个是:13579")
for i in it:
print(i.group())
"""
12345
13579
"""it = re.finditer(r"\d+", "我的电话号码一个是:12345,另一个是:13579")
for i in it:
print(i.group())
"""
12345
13579
"""search:
返回match对象,获取数据需要group(),找到一个结果就返回。
python
s = re.search(r"\d+", "我的电话号码一个是:12345,另一个是:13579")
print(s.group())
# 12345s = re.search(r"\d+", "我的电话号码一个是:12345,另一个是:13579")
print(s.group())
# 12345match:
从头开始匹配与search类似
python
s = re.search(r"\d+", "12345,另一个是:13579")
print(s.group())
# 12345s = re.search(r"\d+", "12345,另一个是:13579")
print(s.group())
# 12345预加载正则表达式
python
obj = re.compile(r"\d+")
rets = obj.finditer("我的电话号码一个是:12345,另一个是:13579")
for ret in rets:
print(ret.group())
"""
12345
13579
"""obj = re.compile(r"\d+")
rets = obj.finditer("我的电话号码一个是:12345,另一个是:13579")
for ret in rets:
print(ret.group())
"""
12345
13579
"""一个样例[选择符合表达式内容的部分内容方法]:
python
import re
s = """
<div class='Jay'><span id='1'>周杰伦</span></div>
<div class='Eason'><span id='2'>陈奕迅</span></div>
<div class='JJ'><span id='3'>林俊杰</span></div>
"""
# (?p<分组名字>正则) 可以单独从正则匹配的内容中进一步提取内容
# re.S 令.能够匹配所有字符
obj = re.compile(r"<div class='.*?'><span id='(?P<top_id>\d+)'>(?P<name>.*?)</span></div>", re.S)
res = obj.finditer(s)
for it in res:
print(it.group('top_id'), it.group('name'))import re
s = """
<div class='Jay'><span id='1'>周杰伦</span></div>
<div class='Eason'><span id='2'>陈奕迅</span></div>
<div class='JJ'><span id='3'>林俊杰</span></div>
"""
# (?p<分组名字>正则) 可以单独从正则匹配的内容中进一步提取内容
# re.S 令.能够匹配所有字符
obj = re.compile(r"<div class='.*?'><span id='(?P<top_id>\d+)'>(?P<name>.*?)</span></div>", re.S)
res = obj.finditer(s)
for it in res:
print(it.group('top_id'), it.group('name'))Python
"""
2022.7.11 Kevin
豆瓣电影排行榜top250爬虫(源代码只能进行前25个电影爬虫,通过while+params解决)
"""
import requests
import re
import csv
st = 0
url = 'https://movie.douban.com/top250'
header = ['电影名', '上映年份', '评分', '评分人数']
with open("ranting.csv", "w", encoding="utf-8", newline='') as fw:
writer = csv.writer(fw)
writer.writerow(header)
while st < 250:
params = {'start': st}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
resp = requests.get(url, headers=headers, params=params)
resp.encoding = 'utf-8'
html = resp.text
obj = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<year>.*?) '
r'.*?<span class="rating_num" property="v:average">(?P<rating>.*?)</span>'
r'.*?<span>(?P<amount>.*?)人评价</span>', re.S)
res = obj.finditer(html)
with open("ranting.csv", "a", encoding="utf-8", newline='') as fw:
writer = csv.writer(fw)
for it in res:
dic = it.groupdict()
dic["year"] = dic["year"].strip()
writer.writerow(dic.values())
st += 25"""
2022.7.11 Kevin
豆瓣电影排行榜top250爬虫(源代码只能进行前25个电影爬虫,通过while+params解决)
"""
import requests
import re
import csv
st = 0
url = 'https://movie.douban.com/top250'
header = ['电影名', '上映年份', '评分', '评分人数']
with open("ranting.csv", "w", encoding="utf-8", newline='') as fw:
writer = csv.writer(fw)
writer.writerow(header)
while st < 250:
params = {'start': st}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
resp = requests.get(url, headers=headers, params=params)
resp.encoding = 'utf-8'
html = resp.text
obj = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<year>.*?) '
r'.*?<span class="rating_num" property="v:average">(?P<rating>.*?)</span>'
r'.*?<span>(?P<amount>.*?)人评价</span>', re.S)
res = obj.finditer(html)
with open("ranting.csv", "a", encoding="utf-8", newline='') as fw:
writer = csv.writer(fw)
for it in res:
dic = it.groupdict()
dic["year"] = dic["year"].strip()
writer.writerow(dic.values())
st += 25结果:
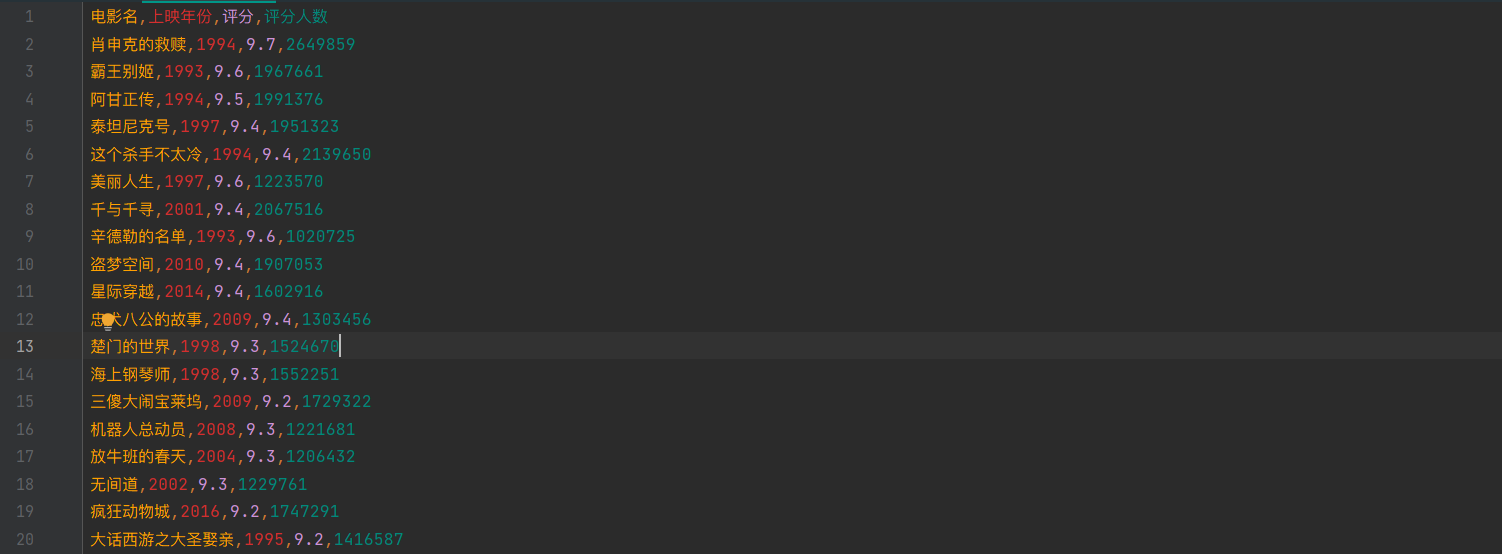

python
"""
2022.7.11 Kevin
爬取电影天堂2022必看电影名称,下载链接
"""
import requests
import re
url = "https://dytt89.com/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
resp = requests.get(url, headers)
resp.encoding = 'gb2312'
html = resp.text
url_list = []
obj1 = re.compile(r"2022必看热片.*?<ul>(?P<ul>.*?)</ul>", re.S)
obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S)
obj3 = re.compile(r'◎片 名(?P<name>.*?)<br />.*?'
r'<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<magnet>.*?)">', re.S)
res1 = obj1.finditer(html)
for it in res1:
ul = it.group('ul')
res2 = obj2.finditer(ul)
for it2 in res2:
new_url = url+it2.group('href').strip('/')
url_list.append(new_url)
#resp2 = requests.get(new_url, headers=headers)
# resp2.encoding = 'gb2312'
# res3 = obj3.finditer(resp2.text)
# for it3 in res3:
# print(it3.group('name'), it3.group('magnet'))
# break
for href in url_list:
child_resp = requests.get(href, headers=headers)
child_resp.encoding = 'gb2312'
res3 = obj3.search(child_resp.text)
print(res3.group('name'), res3.group('magnet'))"""
2022.7.11 Kevin
爬取电影天堂2022必看电影名称,下载链接
"""
import requests
import re
url = "https://dytt89.com/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
resp = requests.get(url, headers)
resp.encoding = 'gb2312'
html = resp.text
url_list = []
obj1 = re.compile(r"2022必看热片.*?<ul>(?P<ul>.*?)</ul>", re.S)
obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S)
obj3 = re.compile(r'◎片 名(?P<name>.*?)<br />.*?'
r'<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<magnet>.*?)">', re.S)
res1 = obj1.finditer(html)
for it in res1:
ul = it.group('ul')
res2 = obj2.finditer(ul)
for it2 in res2:
new_url = url+it2.group('href').strip('/')
url_list.append(new_url)
#resp2 = requests.get(new_url, headers=headers)
# resp2.encoding = 'gb2312'
# res3 = obj3.finditer(resp2.text)
# for it3 in res3:
# print(it3.group('name'), it3.group('magnet'))
# break
for href in url_list:
child_resp = requests.get(href, headers=headers)
child_resp.encoding = 'gb2312'
res3 = obj3.search(child_resp.text)
print(res3.group('name'), res3.group('magnet'))