Request库的使用方法
Request库
获取http网页的主要方法,对应http的get。
requests.get(url, params=None, **kwargs)
TIP
用于发送查询字符串,一般为字典或者字节流格式。
requests.get方法在发起请求之前,会先对params查询参数进行编码,编码后的查询参数会自动的和base_url进行拼接,拼接成一个完整的url地址后,再向网站发起请求。
python
>>> url = 'https://www.baidu.com/s'
>>> values = {
>>> 'wd':'python'
>>> }
>>> resp = requests.get(url, params=values)
>>> resp.url
'https://www.baidu.com/s?wd=python'>>> url = 'https://www.baidu.com/s'
>>> values = {
>>> 'wd':'python'
>>> }
>>> resp = requests.get(url, params=values)
>>> resp.url
'https://www.baidu.com/s?wd=python'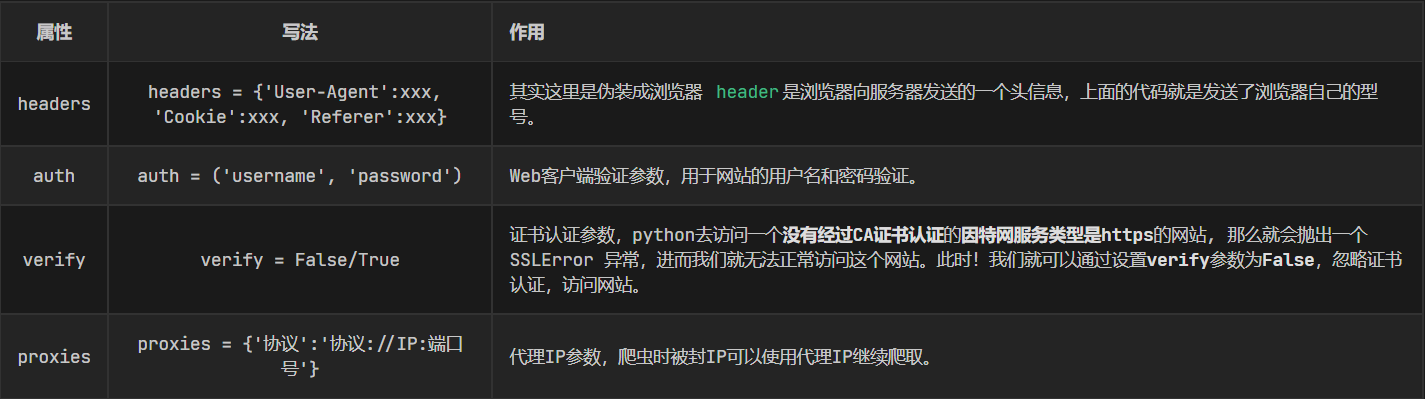

一个样例:
python
"""
2022.7.9 Kevin
爬取一个百度搜索的内容
"""
import requests
s = input("请输入需要查询的内容")
#headers内容可以从控制台的Network查看
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
#kv的具体键值对可以通过具体网页观察url
kv = {'wd' : s}
url = 'https://www.baidu.com/s'
r = requests.get(url, params=kv, headers=headers)
r.encoding = r.apparent_encoding #r.encoding = 'utf-8'
print(r.url)
print(r.text)"""
2022.7.9 Kevin
爬取一个百度搜索的内容
"""
import requests
s = input("请输入需要查询的内容")
#headers内容可以从控制台的Network查看
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
#kv的具体键值对可以通过具体网页观察url
kv = {'wd' : s}
url = 'https://www.baidu.com/s'
r = requests.get(url, params=kv, headers=headers)
r.encoding = r.apparent_encoding #r.encoding = 'utf-8'
print(r.url)
print(r.text)python
"""
2022.7.13 Kevin
处理Cookie模拟用户登录
1.登录 -> 得到Cookie
2.带着Cookie 去请求书架的url -> 书架上的内容
必须把以上操作连起来
可以使用session进行请求 -> session可以认为是一连串的请求,在这个过程中Cookie不会消失
"""
import requests
session = requests.session()
# 1.登录
url = 'https://passport.17k.com/ck/user/login'
resp = session.post(url, data={'loginName': '13433947627', 'password': 'EasonChan0830'})
# print(resp.cookies) # 看cookie
# 2.数据处理
# 刚刚的会话session中是有cookie的
resp2 = session.get('https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919')
print(resp2.json())
# 以上可以用下面内容代替
headers = {
'Cookie': 'XXX' # 从控制台Header里面复制
}
resp = requests.get('https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919', headers= headers)
print(resp.json())"""
2022.7.13 Kevin
处理Cookie模拟用户登录
1.登录 -> 得到Cookie
2.带着Cookie 去请求书架的url -> 书架上的内容
必须把以上操作连起来
可以使用session进行请求 -> session可以认为是一连串的请求,在这个过程中Cookie不会消失
"""
import requests
session = requests.session()
# 1.登录
url = 'https://passport.17k.com/ck/user/login'
resp = session.post(url, data={'loginName': '13433947627', 'password': 'EasonChan0830'})
# print(resp.cookies) # 看cookie
# 2.数据处理
# 刚刚的会话session中是有cookie的
resp2 = session.get('https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919')
print(resp2.json())
# 以上可以用下面内容代替
headers = {
'Cookie': 'XXX' # 从控制台Header里面复制
}
resp = requests.get('https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919', headers= headers)
print(resp.json())向网页提交post申请的方法,对应http的post。requests.post(url, data={key: value}, **kwargs)
python
>>> url = 'https://fanyi.baidu.com'
>>> values = {
'wd':'python'
}
>>> resp = requests.post(url, data=values)>>> url = 'https://fanyi.baidu.com'
>>> values = {
'wd':'python'
}
>>> resp = requests.post(url, data=values)python
"""
7.9 Kevin
爬取一个百度翻译的内容
"""
import requests
s = input('请输入你需要翻译的内容\n')
params = {'kw': s}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
url = 'https://fanyi.baidu.com/sug'
resp = requests.post(url, data=params)
print(resp.json())"""
7.9 Kevin
爬取一个百度翻译的内容
"""
import requests
s = input('请输入你需要翻译的内容\n')
params = {'kw': s}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
url = 'https://fanyi.baidu.com/sug'
resp = requests.post(url, data=params)
print(resp.json())另一个实例(爬取豆瓣电影排行榜):
步骤
1.进入douban.com打开控制台观察浏览器控制台的network。
2.进入Fetch/XDR观察(简化资源视图),从中找到所需的json库的url等属性,观察request method(get/post)
3.复制url,url"?"后方的可以通过payload得到,post为getdata,get为parameters,通过字典赋值可以简化url。
4.通过requests.get()/requests.post()得到resp,用resp.text测试是否爬取正常,一般反爬需要加入Headers属性,中间的User-Agent仿造浏览器访问界面。
实现代码:
Python
"""
7.11 Kevin
豆瓣电影排行榜爬虫
"""
import requests
url = 'https://movie.douban.com/j/chart/top_list'
params = {
#其中start和limit属性可切换,start为排行榜的开始位数-1,limit为一次性爬取的电影数量
'type': '24',
'interval_id': '100:90',
'action': "",
'start': '0',
'limit': '60'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
resp = requests.get(url, params=params, headers=headers)
print(resp.json())
resp.close() #关闭请求"""
7.11 Kevin
豆瓣电影排行榜爬虫
"""
import requests
url = 'https://movie.douban.com/j/chart/top_list'
params = {
#其中start和limit属性可切换,start为排行榜的开始位数-1,limit为一次性爬取的电影数量
'type': '24',
'interval_id': '100:90',
'action': "",
'start': '0',
'limit': '60'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
resp = requests.get(url, params=params, headers=headers)
print(resp.json())
resp.close() #关闭请求