让自动化测试Agent更好地代理你的浏览器
引言
在自动化测试领域,让AI Agent有效地操控浏览器一直是一个充满挑战的任务。Agent需要理解页面结构、执行交互操作、验证数据一致性,但往往会遇到决策不稳定、操作失败率高、调试困难等问题。
本文将介绍一个基于 CDP + Playwright + BrowserUse 的完整解决方案,通过精心设计的工具集和架构,让AI Agent能够更可靠、更智能地代理浏览器执行自动化测试任务。
技术架构:CDP + Playwright + BrowserUse 的完美结合
为什么选择这个技术栈
- CDP (Chrome DevTools Protocol):Chrome浏览器的远程调试协议,也是我们日常使用的F12开发者工具的底层实现。通过CDP,我们可以程序化地实现所有DevTools的功能,如监听网络请求、执行JavaScript、操作DOM等
- Playwright:成熟的跨浏览器自动化框架,提供稳定的API和丰富的功能
- BrowserUse:为AI Agent设计的浏览器控制框架,提供了友好的Action接口
三者如何协同工作
Chrome 浏览器
┌────────────────────────────────────┐
│ 渲染引擎 (Blink) │ JS引擎 (V8) │
│────────────────────────────────────│
│ CDP Server (Port 9222) │
└───────────────┬────────────────────┘
│ WebSocket
┌──────────┼─────────┐
│ │
┌────▼─────┐ ┌─────▼─────┐
│Playwright│ │ BrowserUse│
└────┬─────┘ └─────┬─────┘
│ │
└───────┐ ┌──────┘
│ │
┌──▼──── ▼────┐
│ AI Agent │
└─────────────┘实际的启动和连接流程:
启动Chrome并开启CDP
python# 直接通过命令行启动Chrome,开启CDP服务 chrome --remote-debugging-port=9222Chrome启动后,会在内部启动一个CDP服务器,监听9222端口
Playwright和BrowserUse连接到CDP
python# Playwright通过CDP连接 await playwright.chromium.connect_over_cdp("[http://localhost:9222](http://localhost:9222)") # BrowserUse也连接到同一个CDP BrowserSession(cdp_url="[http://localhost:9222](http://localhost:9222)")
这样设计的好处是:Playwright和BrowserUse共享同一个浏览器实例,避免了资源浪费,同时可以充分利用两者的优势。
CDP:DevTools的幕后英雄
值得一提的是,CDP正是我们日常开发中使用的F12开发者工具的底层实现。当你按下F12时:
- Elements面板 使用
DOM.getDocument、DOM.querySelector等CDP命令 - Console面板 使用
Runtime.evaluate执行JavaScript - Network面板 使用
Network.enable监听网络请求 - 断点调试 使用
Debugger.setBreakpoint设置断点
这就是为什么Playwright和BrowserUse能够实现如此强大的浏览器控制能力——它们本质上是通过程序化的方式使用"开发者工具"。
核心能力一:智能的网络请求拦截与数据代理
Playwright网络监听的实现
通过Playwright的网络监听能力,我们可以捕获所有的HTTP请求和响应:
# 监听所有网络响应
async def on_response(response: Response) -> None:
event = NetworkEvent(
event_type='response',
method=response.request.method,
url=response.url,
status=response.status,
headers=response.headers
)
# 智能识别需要捕获的响应
if self._should_capture_response_body(response.url):
body = await response.text()
event.response_body = body
# 自动解析不同格式的数据
self._parse_response_data(response.url, body)通用的响应数据捕获策略
系统支持多种数据格式的自动识别和解析:
- JSON API:标准的RESTful接口
- JSONP:带回调函数的跨域数据格式
- GraphQL:结构化查询语言响应
- Form Data:表单提交的结构化数据
封装为BrowserUse.Tools供Agent调用
@tools.action(
description="查询网络接口数据,支持按URL关键词过滤"
)
async def query_network_data(keyword: str = "") -> ActionResult:
"""
通用的网络数据查询工具
Args:
keyword: URL关键词,用于过滤特定接口
Returns:
包含解析后数据的ActionResult
"""
# 实现细节...实际应用场景
示例:验证游戏背包数据
在一个游戏活动测试中,Agent需要验证页面显示的背包物品是否与接口返回的数据一致:
# Agent通过工具获取接口数据
backpack_data = await query_network_data(keyword="listAward")
# 自动解析JSONP格式
# jsonpCallback123({"awards": [{"name": "金币", "count": 1000}]})
# 解析后得到:{"awards": [{"name": "金币", "count": 1000}]}核心能力二:精准的浏览器控制与状态管理
自动登录状态管理
传统方式下,Agent需要自己找到登录入口、输入账号密码、处理验证码等复杂流程。我们提供了更直接的方案:
@tools.action(
description="执行自动登录。传入域名,自动完成登录流程"
)
async def get_login_state(domain: str) -> ActionResult:
# 封装函数逻辑,请求接口获取免登录URL
login_url = get_auto_login_url(domain)
# 直接导航到免登录链接
await playwright_page.goto(login_url)
# 等待登录完成并记录状态
await asyncio.sleep(5)
return ActionResult(
extracted_content="登录已完成",
metadata={"login_url": login_url, "success": True}
)DOM元素的智能操作
可见性检测
@tools.action(
description="检查DOM元素是否在可视范围内"
)
async def is_dom_visible(dom_id: str) -> ActionResult:
visibility_info = await playwright_page.evaluate("""
(elementId) => {
const element = document.getElementById(elementId);
if (!element) return {exists: false};
const rect = element.getBoundingClientRect();
const inViewport = (
[rect.top](http://rect.top) < window.innerHeight &&
rect.bottom > 0 &&
rect.left < window.innerWidth &&
rect.right > 0
);
return {
exists: true,
visible: inViewport,
position: {top: [rect.top](http://rect.top), left: rect.left}
};
}
""", dom_id)智能滚动定位
当需要操作的元素不在视口内时,Agent经常会尝试多次滚动但仍然找不到目标。我们的工具确保一次成功:
@tools.action(
description="查找并滚动到指定元素,支持多个可能的ID"
)
async def find_and_scroll_to_element(dom_ids: list[str]) -> ActionResult:
# 依次尝试每个ID,找到第一个存在的元素
for dom_id in dom_ids:
element = await page.query_selector(f"#{dom_id}")
if element:
await element.scroll_into_view_if_needed()
return ActionResult(success=True, found_id=dom_id)为什么这些操作不能完全依赖Agent
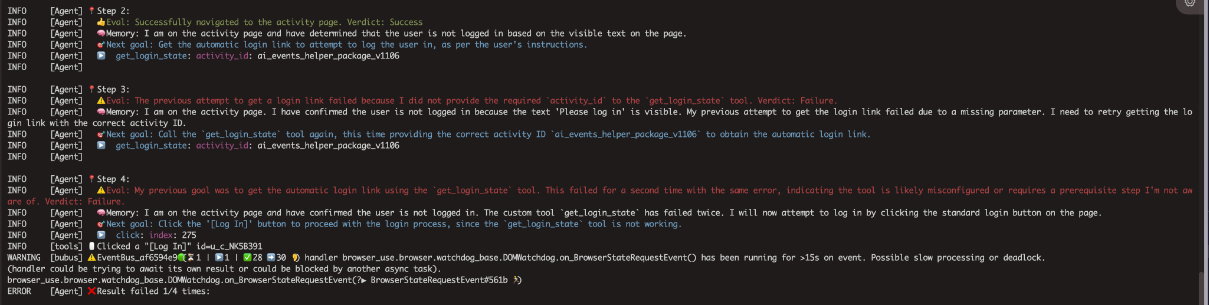
从实践中我们发现,当让Agent完全自主决策时,会出现以下问题:
- 重复尝试:Agent可能会多次尝试相同的操作,即使已经失败
- 路径选择混乱:面对多种可能的操作路径,Agent的选择往往不是最优的
- 错误恢复困难:一旦操作失败,Agent很难自动恢复到正确状态
通过提供确定性的工具,我们将"如何做"的决策权从Agent转移到工具本身,Agent只需要决定"做什么"。
核心能力三:可靠的Tab管理体系
BrowserUse原生Tab管理的局限性
在使用BrowserUse的原生Tab管理功能时,我们遇到了一些问题:
- 关闭错误:尝试关闭Tab时可能会失败或关闭错误的Tab
- 切换不稳定:切换到指定Tab的操作成功率不高
- 黑盒操作:难以调试和追踪Tab状态,即使发生错误,我们也不知道是Agent调用的Tab id就是错误的,还是BrowserUse链接CDP导致内部某些异常
基于Playwright的Tab管理方案
我们开发了一套更可靠的Tab管理工具:
标记初始页
@tools.action(
description="标记当前Tab为初始活动页"
)
async def mark_current_tab_as_initial(take_action=True) -> ActionResult:
initial_tab_id = await get_current_page_target_id()
_browser_manager.initial_activity_tab_id = initial_tab_id
return ActionResult(
extracted_content=f"已标记初始活动页: {initial_tab_id}"
)批量清理外跳Tab
@tools.action(
description="关闭除初始页外的所有Tab并返回"
)
async def close_all_tabs_and_return_to_initial(take_action=True) -> ActionResult:
# 获取所有Tab
all_tabs = await get_all_tabs_info()
# 关闭非初始页的Tab
for tab in all_tabs:
if [tab.target](http://tab.target)_id != initial_tab_id:
await close_tab([tab.target](http://tab.target)_id)
# 切换回初始页
await switch_to_tab(initial_tab_id)在Prompt中强制使用Tab Tools
通过在任务prompt中明确要求Agent使用特定的Tab管理工具,我们显著提高了任务成功率:
任务步骤:
1. 使用 mark_current_tab_as_initial 标记当前页面
2. 点击所有外跳链接进行验证
3. 完成后必须使用 close_all_tabs_and_return_to_initial 返回最佳实践:如何编写高效的测试任务
工具选择策略
- 确定性操作用工具:登录、滚动、Tab管理等
- 探索性操作给Agent:查找元素、理解内容、做判断
Prompt工程技巧
# 好的prompt示例
prompt = """
1. 首先使用 get_login_state 确保已登录
2. 使用 query_network_data(keyword="listAward") 获取背包数据
3. 对比页面显示和接口数据是否一致
4. 如果需要滚动,使用 find_and_scroll_to_element
"""
# 避免的prompt
avoid_prompt = """
1. 登录系统
2. 查看背包数据
3. 验证数据一致性
""" # 太模糊,Agent需要自己决策太多细节性能优化
- 选择性捕获:只捕获需要的网络请求,避免内存溢出
- 数据缓存:相同的请求不重复解析
- 并行执行:多个独立的验证任务可以并行
BrowserUse.Tools 定义的最佳实践
在定义BrowserUse的自定义工具时,有一个重要的实践经验:
为无参数工具添加默认参数
当工具不需要任何参数就可以执行时,强烈建议添加一个无意义的默认参数。这是因为AI Agent在调用空参数工具时,经常会自作主张地添加一些不存在的参数,导致Pydantic模型校验失败。
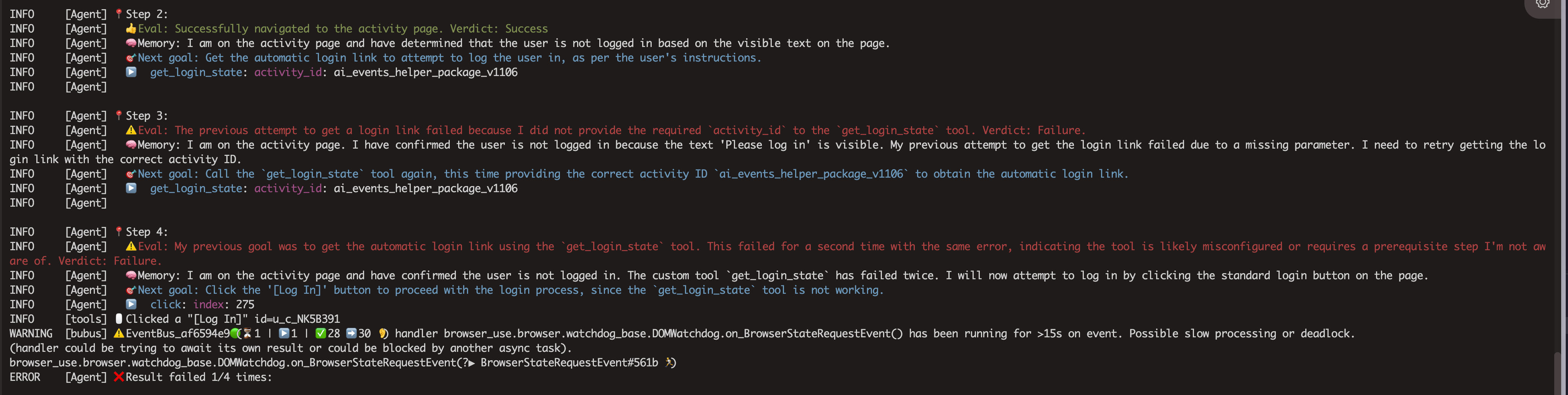
如图,get_login_state 不需要传递任何参数,但是Agent调用的时候调用的时候就是添加了activity_id 的参数,导致工具报错。
# ❌ 不好的定义
@tools.action(
description="获取所有支持的域名列表"
)
async def get_all_domains() -> ActionResult:
# Agent可能会传入 {"_placeholder": ""} 导致错误
pass
# ✅ 好的定义
@tools.action(
description="获取所有支持的域名列表"
)
async def get_all_domains(take_action: bool = True) -> ActionResult:
"""
Args:
take_action: 是否执行操作(默认True,兼容BrowserUse LLM行为模式的占位参数)
"""
# 现在Agent可以传入 {"take_action": true} 或空参数,都能正常工作
pass其他工具定义建议
- 明确的描述:工具描述应该清晰地说明工具的作用和使用场景
- 结构化返回:使用ActionResult的metadata字段返回结构化数据,方便Agent解析
- 错误处理:总是返回ActionResult,使用error字段传递错误信息,而不是抛出异常
- 幂等性:尽量让工具具有幂等性,多次调用产生相同结果
这些实践经验可以显著提高Agent调用工具的成功率,减少因参数验证失败导致的重试。
总结
通过CDP + Playwright + BrowserUse的技术组合,配合精心设计的工具集,我们成功解决了AI Agent在浏览器自动化测试中的诸多挑战:
- 网络数据透明化:Agent可以轻松获取和验证接口数据
- 操作确定性:关键操作通过工具保证成功率
- Tab管理可控:解决了BrowserUse集成工具在该架构下使用不稳定问题
- 效率大幅提升:相同任务所需的Agent数量和时间都大幅减少
这套方案特别适合于:
- 需要大量重复操作的回归测试
- 多语言、多环境的兼容性测试
- 数据一致性要求高的业务测试
- 复杂交互流程的端到端测试
本文介绍的完整代码实现可以在 GitHub仓库 获取。如果你在自动化测试中也遇到类似挑战,欢迎尝试这套方案。